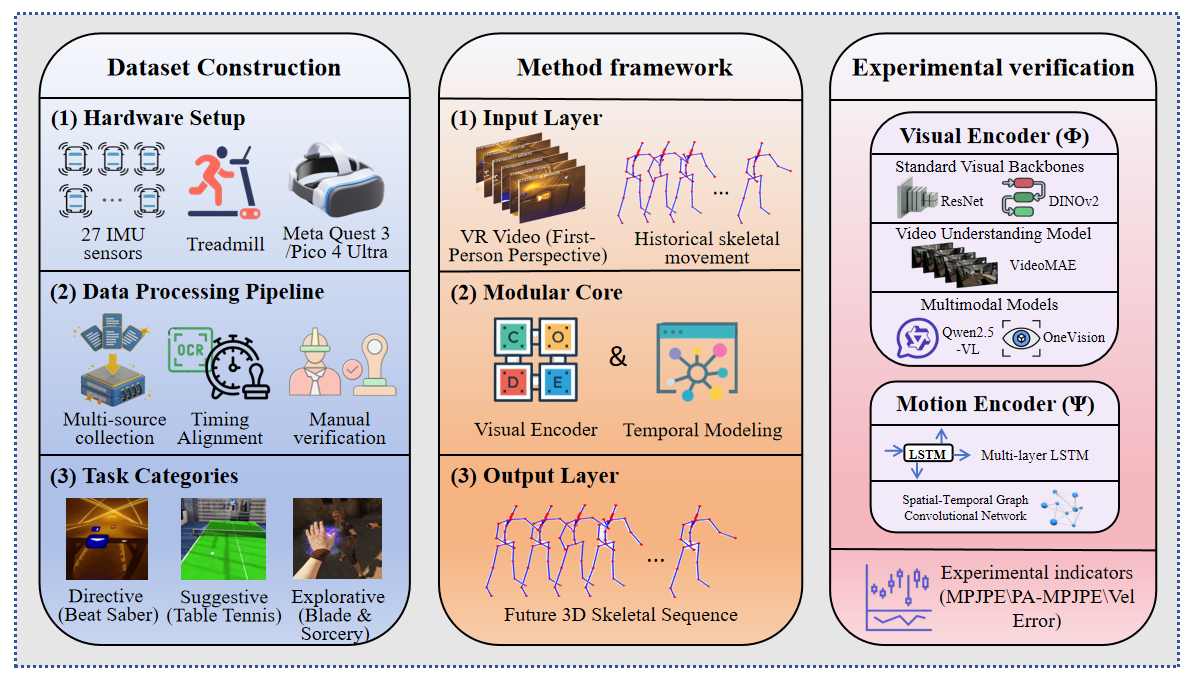
Showing the VRMotion framework overview VRMotion is a large-scale multimodal dataset for exploring egocentric visual-full-body motion causality, built with 27 IMUs, an omnidirectional treadmill, and VR headsets to solve marker occlusion and spatial constraints, containing 21.6 million synchronized frames across three cognitive-complexity tasks after timestamp alignment and manual verification. The accompanying end-to-end modular framework formalizes motion prediction as cross-modal synthesis, processing VR video and historical skeletal motion, extracting spatial features via a Visual Encoder and modeling temporal dynamics, then outputting future 3D skeletons to shift from reactive to proactive motion anticipation. Systematic benchmarking of 10 visual backbone-temporal head combinations (including LVLMs like Qwen2.5-VL and heads like LSTM/ST-GCN) with MPJPE, PA-MPJPE, and Velocity Error shows LVLMs outperform traditional models, with Qwen2.5-VL + LSTM achieving state-of-the-art performance.
Abstract
As artificial intelligence systems increasingly interact with humans in physical environments, understanding the causal relationship between visual perception and full-body motor responses becomes critical for safe and natural human-AI collaboration. However, existing motion datasets either lack visual context or are constrained by marker occlusion and limited capture volumes in large-scale scenarios.
We present VRMotion, a large-scale multimodal dataset that captures temporally aligned egocentric visual stimuli and corresponding full-body kinematic responses. We leverage VR environments to safely simulate diverse task scenarios, while an omnidirectional treadmill combined with a 27-sensor IMU system enables occlusion-free capture of unconstrained locomotion with consistent precision.
Dataset Statistics
Key Features
🎯 Multimodal Synchronization
Precisely aligned egocentric video (30fps) and full-body IMU data (60Hz) capturing the causal relationship between visual stimuli and motor responses.
🚶 Unconstrained Locomotion
Omnidirectional treadmill enables natural walking patterns without physical space constraints or marker occlusion issues.
🎮 Diverse Task Scenarios
Three cognitive complexity levels: Directive (Beat Saber), Suggestive (Table Tennis), and Explorative (Blade & Sorcery).
📊 High-Fidelity Capture
27 wireless IMU sensors with 0.1° rotational accuracy, capturing fine-grained finger movements and full-body kinematics.
Data Acquisition System

Figure 1: Motion capture system, VR suite, and omnidirectional treadmill Visualization of the data acquisition equipment. The left part shows a schematic diagram of the wearable motion capture system, which consists of 17 inertial sensors with gyroscopes and two data gloves for capturing full-body and fine- grained finger movements. The middle part presents a real-world example of a participant wearing the complete setup. The right part displays the joint visualization generated by the industrial-grade software Axis Studio after calibration and reconstruction.
Components
Motion Capture System
27 wireless IMU sensors (gyroscope, accelerometer, magnetometer) at 60Hz with 0.1° accuracy
VR System
Meta Quest 3 / Pico 4 Ultra with 2160×2160 per eye at 90Hz
Omnidirectional Treadmill
Virtuix Omni One capturing walking direction, speed, and acceleration at 100Hz
Data Processing Pipeline
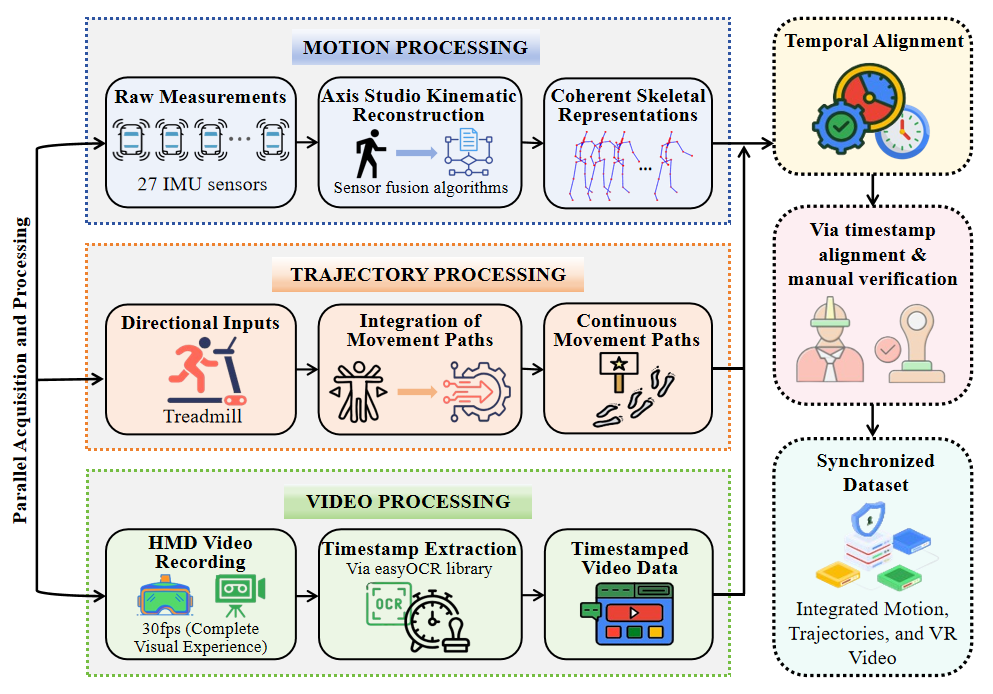
Figure 2: Motion processing, trajectory processing, video processing, and temporal alignment The VRMotion data processing pipeline consists of four stages: first, raw measurements from 27 IMU sensors are captured at 60Hz, and motion reconstruction is performed using Axis Studio sensor fusion algorithms to generate coherent skeletal representations; second, directional inputs from the treadmill are integrated to construct continuous movement trajectories that accurately reflect participants’ navigation intentions in the virtual environment; third, the full visual experience is recorded via the head-mounted display at 30fps, and timestamps are extracted using the easyOCR library; finally, multimodal data streams are temporally aligned based on the timestamps, followed by strict manual verification to filter out artifacts and ensure reliable causal synchronization.
Task Categories

Directive (Beat Saber)
Highly directive tasks with explicit visual cues that strongly correlate with expected user responses, primarily focusing on upper body movements in a relatively stationary position.

Suggestive (Table Tennis)
Suggestive tasks providing contextual cues that require interpretation and personalized responses, introducing moderate locomotion requirements.

Explorative (Blade & Sorcery)
Explorative tasks with open-ended interaction and minimal constraints, requiring substantial environmental awareness and spatial cognition enabled by the treadmill.
Dataset Analysis
3D Joint Trajectories
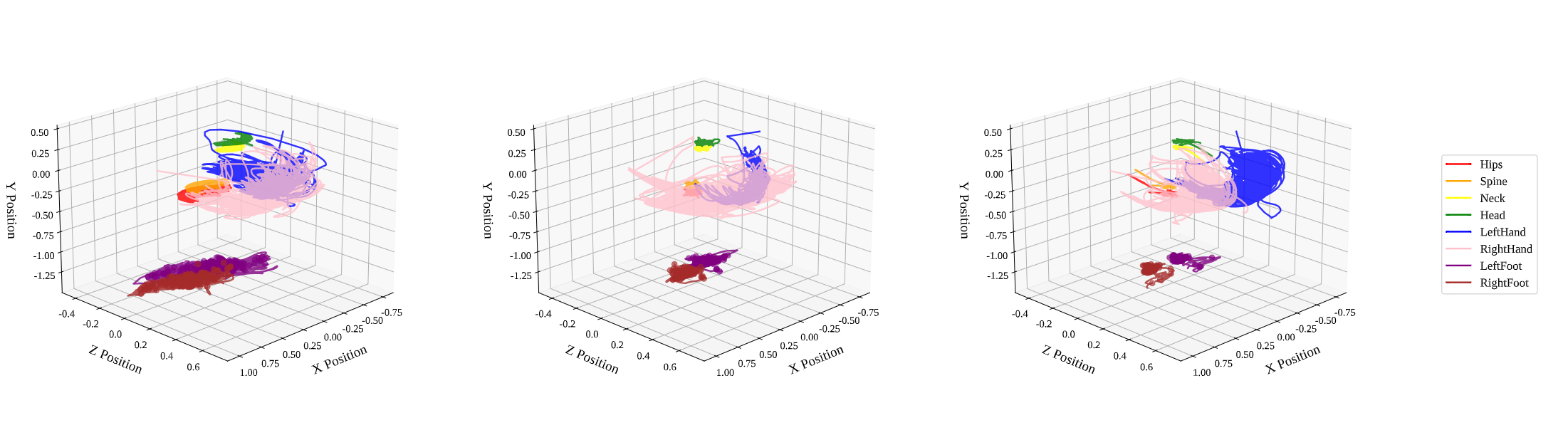
Figure 3: Spatial paths across Blade & Sorcery, Table Tennis, and Beat Saber 3D trajectories reveal task-specific spatial organization and the impact of hardware on movement realism. Blade & Sorcery exhibits en- larged trajectory envelopes across all joints, particularly the lower limbs, which is a direct result of natural locomotion on the omni- directional treadmill. Unlike controller-based datasets, VRMotion captures these high-fidelity navigational intentions, providing rich targets for models trained to forecast future trajectories from visual cues.
Cumulative Joint Displacement
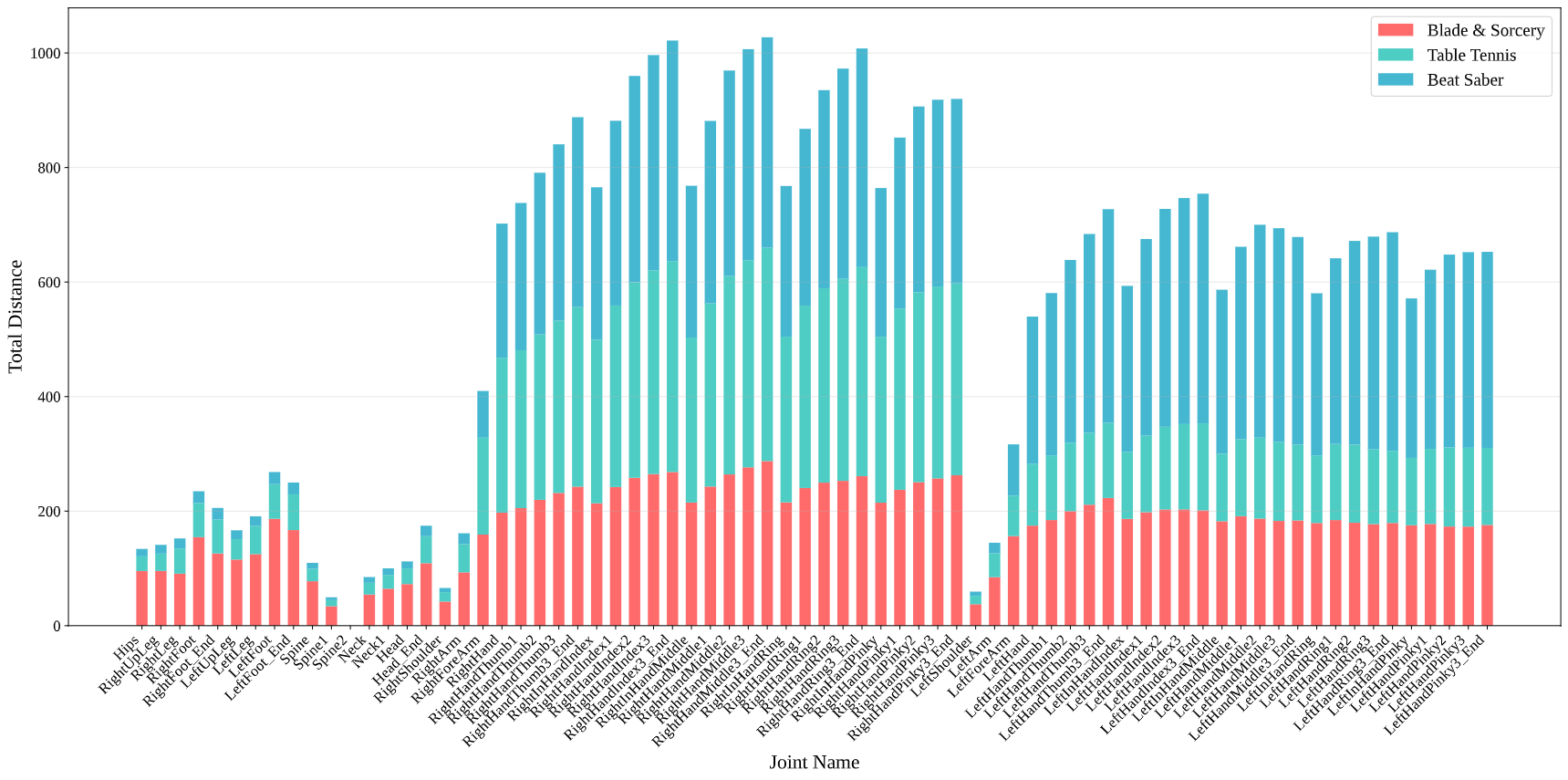
Figure 4: Stacked bar chart showing task-specific movement emphasis The stacked cumulative displacement identify segments that dominate overall movement, directly impacting prediction error weighting. As reflected in the proportional segments of the bars, in the directive Beat Saber task, hand joints overwhelmingly lead with displace- ments 18.3x that of body joints. Conversely, the explorative Blade & Sorcery task distributes effort more broadly (hands 2.2x body joints) due to integrated locomotion. These profiles indicate that predictive precision in high-displacement joints is critical for system-level performance.
Gaze-Trajectory Synergy
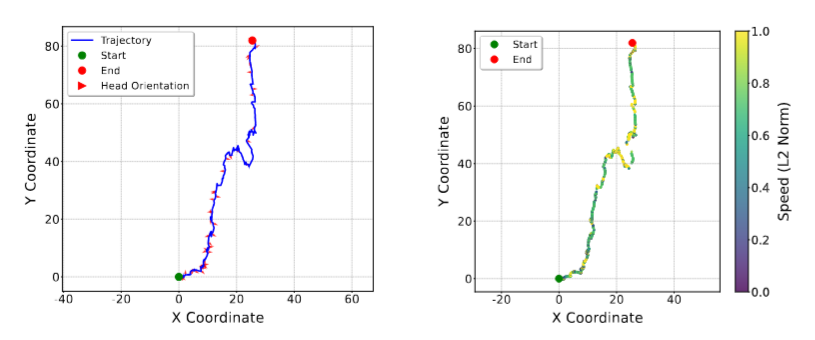
Figure 5: Relationship between viewing behavior and locomotion dynamics Analysis of the explorative scenario reveals a consistent speed-gaze trade-off: intensive exploratory scanning coincides with reduced forward speed, while speed in- creases when gaze aligns with the locomotion path. This relation- ship establishes egocentric field-of-view (FoV) orientation as a pow- erful contextual cue for predicting near-future velocity and path commitment, enabling the cross-modal predictive capabilities that form the core of the VRMotion framework.
VRMotion Framework
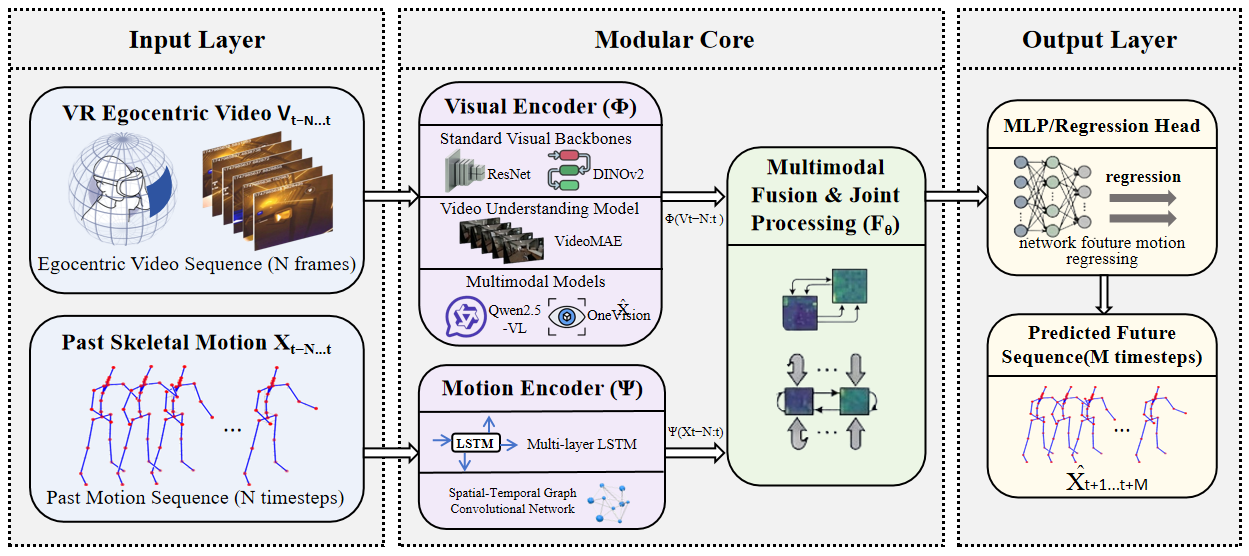
Figure 6: Visual encoder, temporal modeling, and motion prediction pipeline The VRMotion end-to-end cross-modal human motion prediction framework consists of three core modules: the Input Layer receives two types of temporal inputs, namely first-person VR video and historical 3D skeletal motion sequences; the Modular Core processes the two data modalities separately via a dual-encoder architecture (the visual encoder extracts video features, and the motion encoder models temporal motion dynamics), then performs feature collaboration through a multimodal fusion module; finally, the Output Layer generates future 3D skeletal motion sequences via a regression head, enabling proactive prediction of full-body future trajectories from visual inputs and historical motion.
Baseline Models
We evaluate 10 distinct visual-temporal combinations:
Visual Encoders (5 variants)
- LVLMs: Qwen2.5-VL, OneVision
- Vision Transformers: DINOv2, VideoMAE
- CNNs: ResNet
Temporal Heads (2 variants)
- LSTM: Implicit sequence decoder
- ST-GCN: Topology-aware graph network
Experimental Results
Quantitative Comparison
| Visual Encoder | Temporal Model | MPJPE (mm) ↓ | PA-MPJPE (mm) ↓ | Vel Error (mm/f) ↓ |
|---|---|---|---|---|
| Qwen2.5-VL | LSTM | 44.25 | 40.47 | 10.87 |
| OneVision | LSTM | 48.17 | 44.36 | 10.05 |
| DINOv2 | LSTM | 54.66 | 48.63 | 12.38 |
| ResNet | LSTM | 63.48 | 52.92 | 12.43 |
| VideoMAE | LSTM | 90.46 | 64.83 | 15.04 |
| Qwen2.5-VL | ST-GCN | 127.62 | 96.53 | 48.49 |
| OneVision | ST-GCN | 202.84 | 99.91 | 104.26 |
| DINOv2 | ST-GCN | 215.46 | 113.36 | 108.26 |
| VideoMAE | ST-GCN | 268.80 | 144.12 | 108.44 |
| ResNet | ST-GCN | 409.68 | 252.03 | 206.56 |
Key Finding: LVLM-based encoders (Qwen2.5-VL) achieve state-of-the-art accuracy with 44.25mm MPJPE, significantly outperforming traditional CNNs (63.48mm) and video models (90.46mm). LSTM heads consistently outperform ST-GCN across all visual backbones.
Qualitative Results
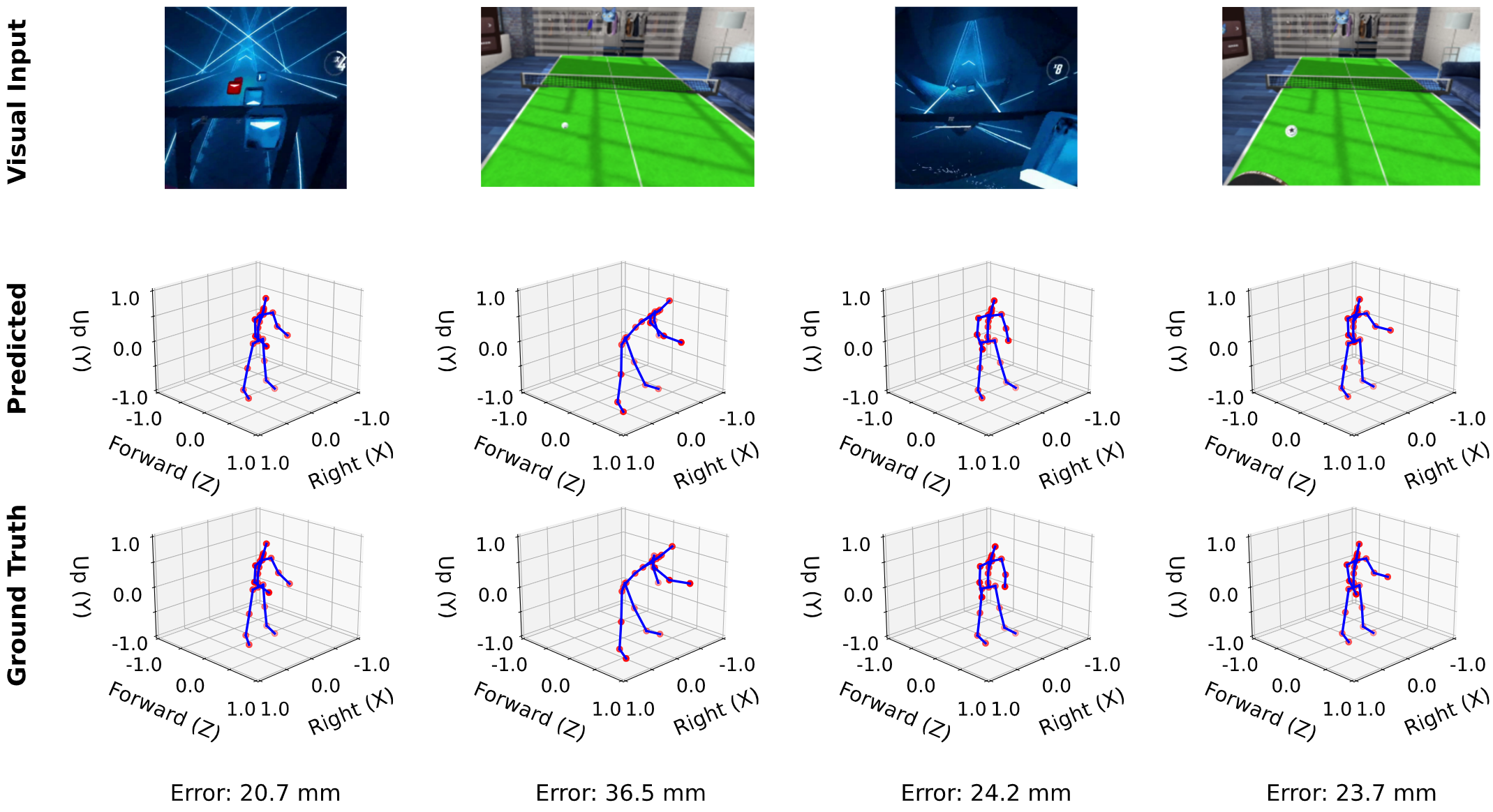
Figure 7: Visual input, predicted pose, and ground truth comparison The qualitative results show that the predicted poses remain highly consistent with the ground truth at a future prediction horizon of 0.53 seconds, with errors ranging only from 20.7 mm to 36.5 mm. Furthermore, the structural alignment between the predicted skeleton and the ground truth indicates that the framework has successfully learned the underlying behavioral intentions behind the visual cues from the first-person VR view.
Supplemental Materials
Directional Speed Heatmaps
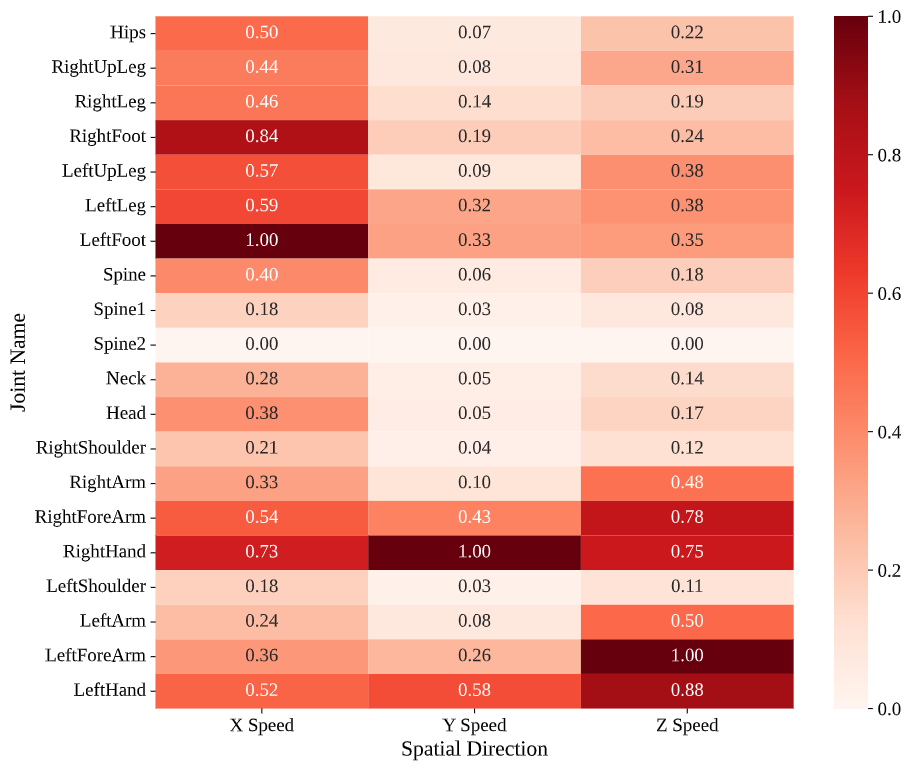
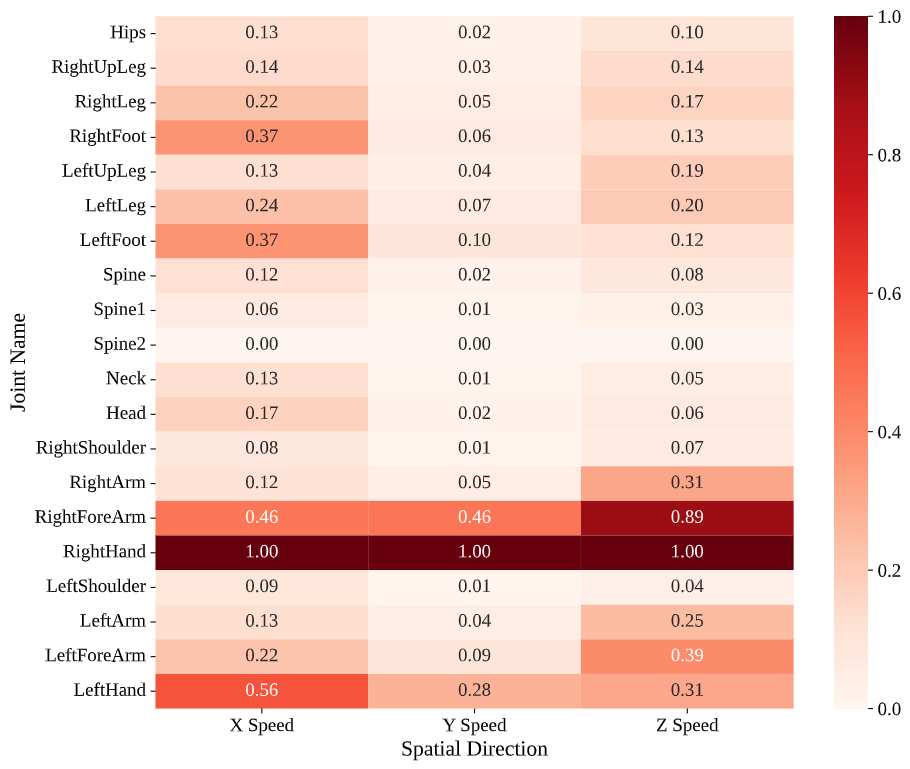
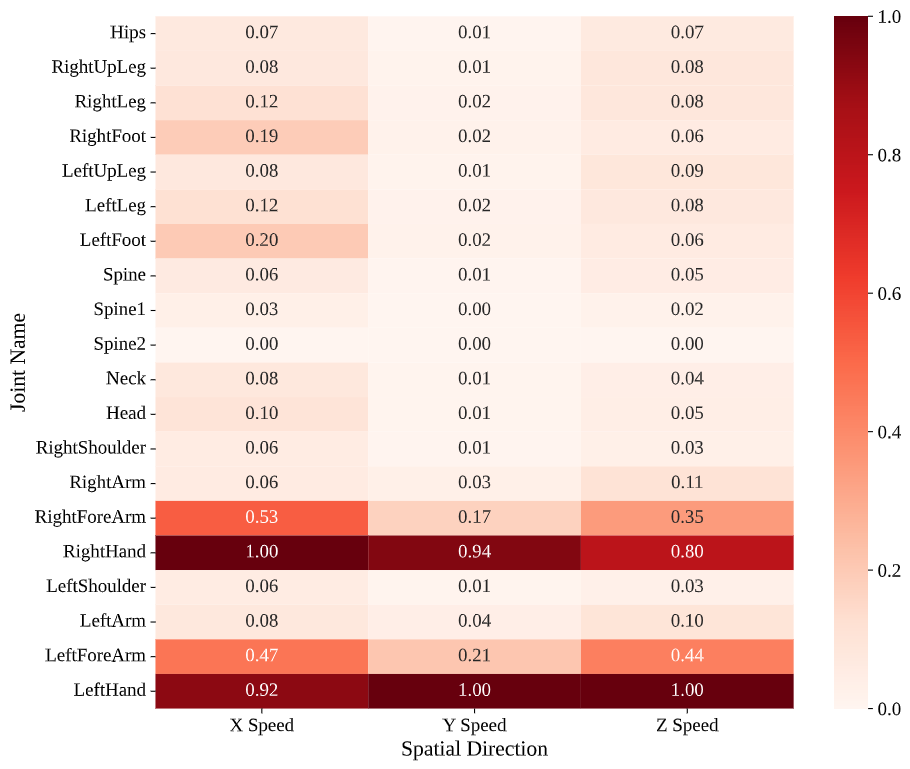
Normalized joint-wise directional speed distributions (Blade & Sorcery, Table Tennis, Beat Saber)
Main-Joint Directional Speed Profiles: Directional speed heatmaps, normalized for comparability, reveal how tasks channel effort through specific kinematic pathways. Beat Saber concentrates velocity in hands and forearms: these segments reach about 4.3%–6.8% in normalized directional speed, while most other joints remain below 1%. The pattern reflects score-driven optimization where users favor rapid, localized hand motions and suppress extraneous body movement. Symmetry persists at the speed level, with both hands exhibiting comparable velocities.
Table Tennis departs from this symmetry. The right hand shows substantially higher average speed, while the left hand remains at roughly 3.7%–5.2% of the right, capturing a unilateral control regime. The rest of the body contributes primarily through supportive rotations and balance rather than high-speed distal actions. Blade & Sorcery displays more distributed speeds across hands and feet, indicating coupled upper–lower-limb engagement. The lower-limb activity is particularly pronounced in the directional speeds, with RightFoot and LeftFoot showing significant activity across all spatial dimensions—a direct result of natural locomotion on the omnidirectional treadmill. Similarity between forearm and hand speeds suggests frequent forward thrusts and two-handed manipulations typical of spears and casting-like gestures. These profiles offer compact cues for model design, where feature weighting can reflect task-specific kinematic concentrations.
Inter-Joint Velocity Correlations
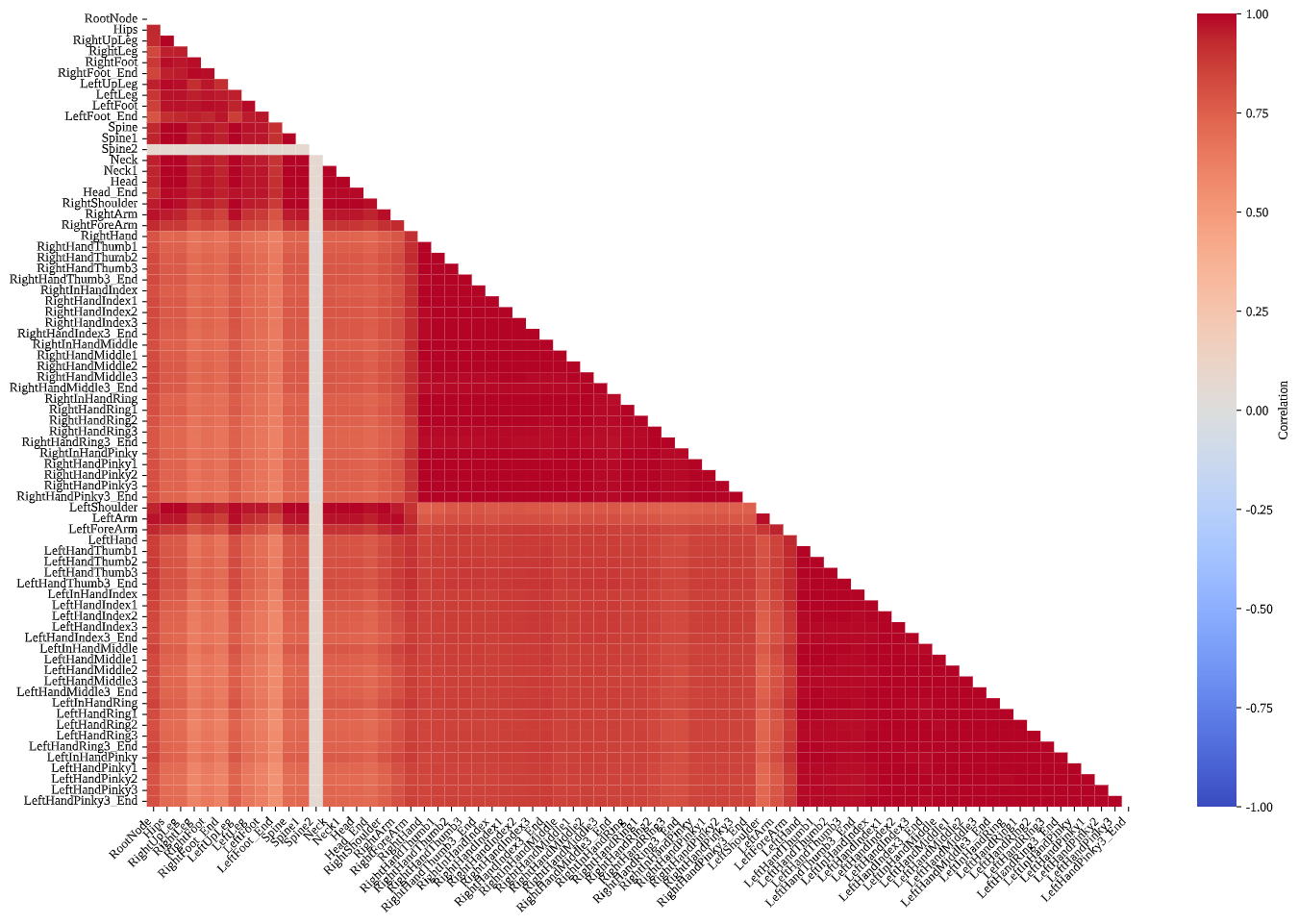
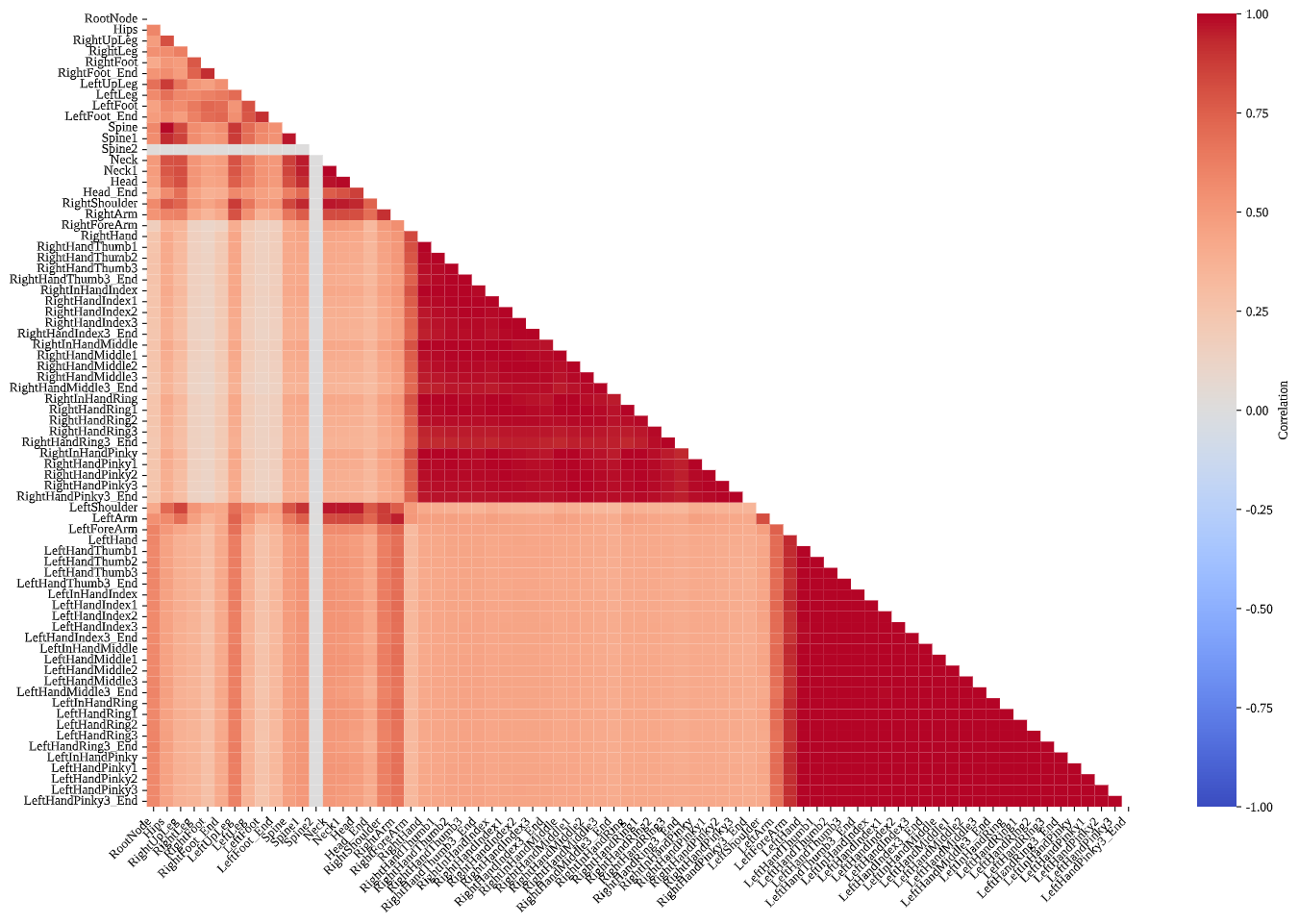
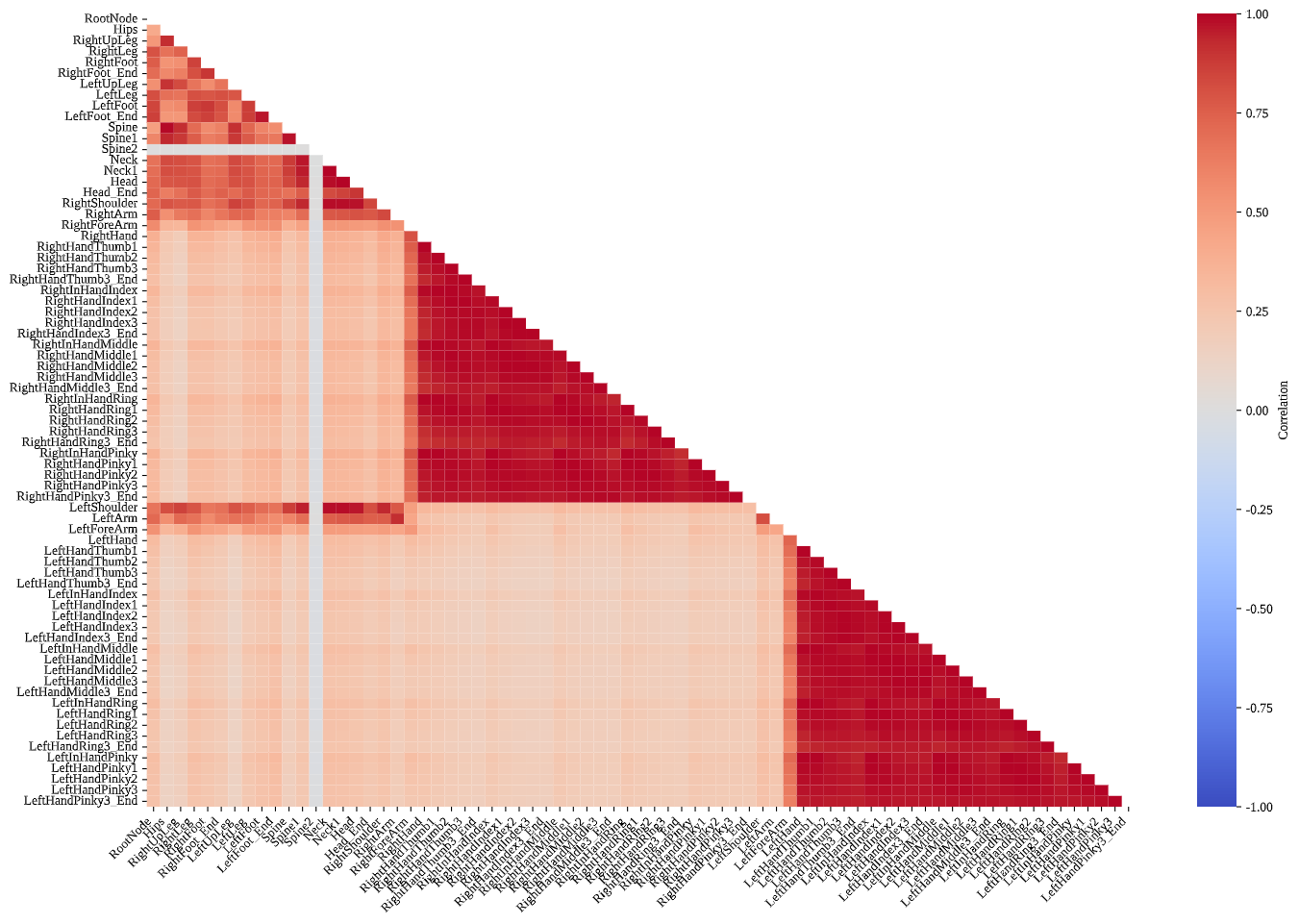
Revealing task-specific kinematic coordination patterns
Inter-Joint Velocity Correlation: Correlation structure captures coordination and functional coupling. In Beat Saber, strong correlations cluster within intra-limb groups of each arm, especially among manual and digital segments, while associations with the rest of the body are weak. The result corroborates a hand-isolated regime wherein non-manual joints maintain low-variance states. Table Tennis retains elevated intra-arm correlations but exhibits stronger associations linking the right arm, shoulders, and upper legs to the rest of the body, reflecting multi-joint synergies for stroke production, balance, and torso-driven power. Blade & Sorcery presents robust bilateral clustering within both arms and legs, indicative of coordinated whole-body dynamics under purposeful navigation and combat.
These patterns suggest opportunities for predictive modeling. Highly correlated joint groups can share representations to reduce redundancy, while task-conditioned correlation profiles can guide adaptive routing for forecasting speed changes, turning maneuvers, and compound actions. In practice, coupling structure can regularize model design and inform loss shaping to respect biomechanical synergies observed across tasks.
Analysis Insights: Beat Saber exhibits hand-isolated motion (hands 18.3× body joints), Table Tennis shows asymmetric control with right-hand dominance, and Blade & Sorcery demonstrates globally coherent full-body coordination (hands 2.2× body joints) with substantial locomotion integration.
Dataset Access & Code
Download Dataset
The VRMotion dataset is publicly available on Hugging Face:
from datasets import load_dataset
# Load the full dataset
dataset = load_dataset("strfysy/VRMotion")
# Access training split
train_data = dataset["train"]Baseline Implementation
Reference implementations are available on GitHub:
# Clone the repository
git clone https://github.com/1530442592-hue/VRMotion-Baselines.git
cd VRMotion-Baselines
# Install dependencies
pip install -r requirements.txt
# Train Qwen2.5-VL + LSTM model
python scripts/train_qwen25_vl_lstm.py --batch_size 16
# Visualize / Evaluate trained model
python scripts/visualize_qwen25_vl_lstm.py --checkpoint path/to/checkpoint.pthDataset Structure
- Raw Motion Data: FBX format with 59-joint hierarchy
- Egocentric Video: 30fps HD recordings from VR headset
- Synchronized Timestamps: Frame-level alignment for causal analysis
- Trajectory Data: Locomotion paths with directional speed at 100Hz
Comparison with Existing Datasets
| Dataset | HMD Content | VR-Motion Alignment | Locomotion | VR Environment | Size (Frames) |
|---|---|---|---|---|---|
| CMU Mocap | ✗ | ✗ | ✗ | ✗ | 15.3M |
| HumanEva | ✗ | ✗ | ✗ | ✗ | 0.08M |
| Human3.6M | ✗ | ✗ | ✗ | ✗ | 3.6M |
| VR-Behavior | ✗ | ✗ | ✗ | ✓ | 26M |
| TotalCapture | ✗ | ✗ | ✗ | ✗ | 1.9M |
| EPIC-KITCHENS | ✓ | ✗ | ✗ | ✗ | 11.5M |
| DIP-IMU | ✗ | ✗ | ✗ | ✗ | 0.3M |
| EGO-CH | ✓ | ✗ | ✗ | ✗ | 0.17M |
| Egobody | ✓ | ✗ | ✗ | ✗ | 0.59M |
| VRMN-bD | ✓ | ✗ | ✗ | ✓ | 0.97M |
| Questset | ✗ | ✗ | ✗ | ✓ | N/A |
| Movement & Traffic | ✗ | ✗ | ✗ | ✓ | N/A |
| VRMotion (Ours) | ✓ | ✓ | ✓ | ✓ | 21.6M |
VRMotion is the first dataset capturing the causal relationship between VR visual stimuli and full-body responses through precise temporal alignment.
Citation
If you find our dataset or framework useful in your research, please cite our paper:
title={VRMotion: A Large-Scale Dataset for Full-Body Motion Prediction in Ego-Vision Tasks},
author={Zhang, Dayou and Song, Yi and Lin, Shufang and Cao, Zijian and Zhang, Rongrong and Wang, Fangxin},
booktitle={Submitted to ACM Multimedia},
year={2026},
}
Acknowledgments
All data collection procedures were approved by the Institutional Review Board of The Chinese University of Hong Kong, Shenzhen (IRB No. CUHKSZ-D-20250059). All participants provided written informed consent prior to participation.